组合总和系列问题的解法。
问题I
给定一个无重复元素的数组 candidates
和一个目标数 target ,找出 candidates
中所有可以使数字和为 target 的组合。
candidates 中的数字可以无限制重复被选取。
说明:
- 所有数字(包括
target)都是正整数。 - 解集不能包含重复的组合。
示例 1:
1 | 输入:candidates = [2,3,6,7], target = 7, |
示例 2:
1 | 输入:candidates = [2,3,5], target = 8, |
提示:
- 1 <= candidates.length <= 30
- 1 <= candidates[i] <= 200
- candidate 中的每个元素都是独一无二的。
- 1 <= target <= 500
思路与算法
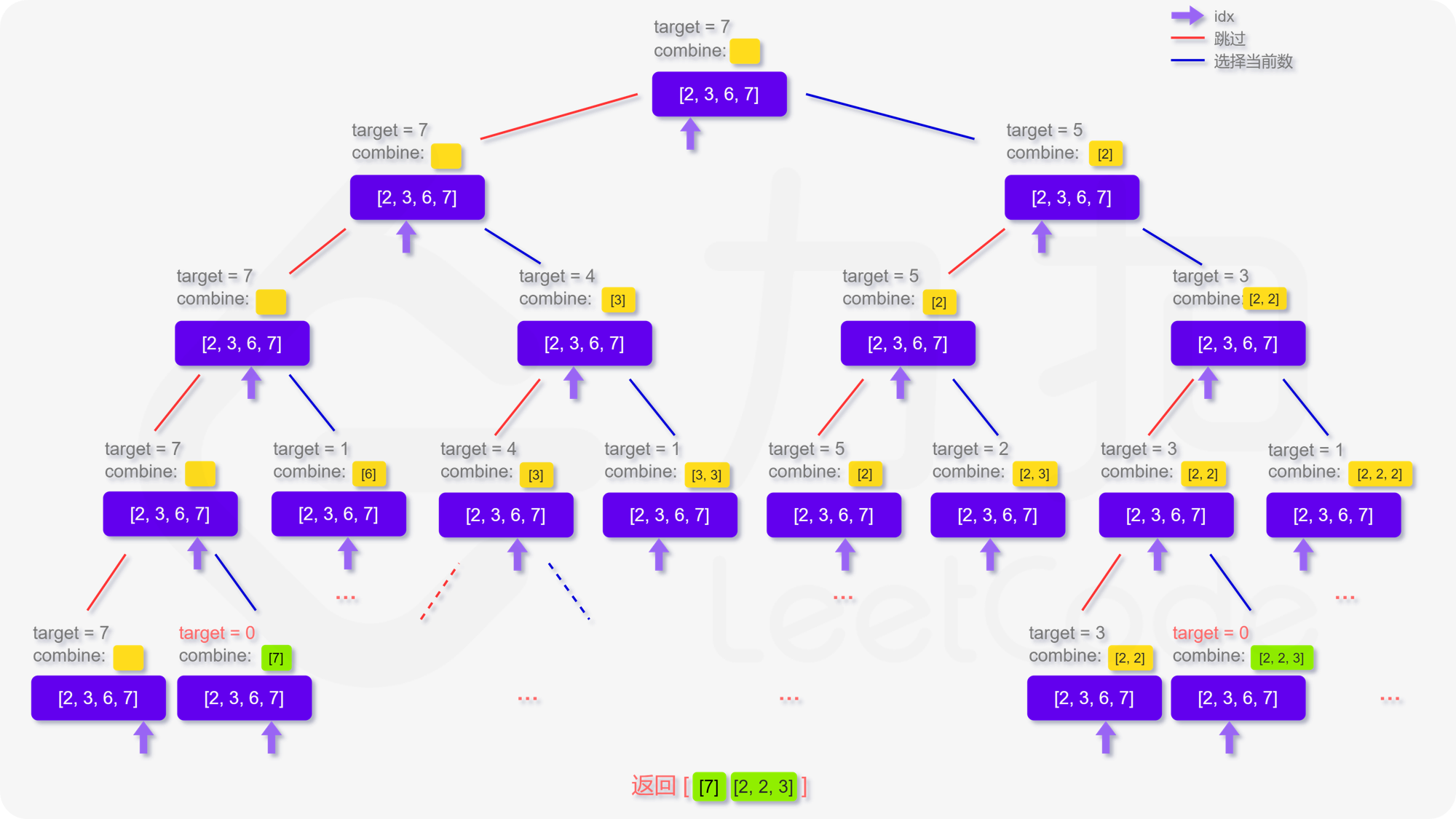
对于这类寻找所有可行解的题,我们都可以尝试用「搜索回溯」的方法来解决。
回到本题,我们定义递归函数 dfs(target, combine, idx)
表示当前在 candidates 数组的第 idx 位,还剩 target
要组合,已经组合的列表为 combine。递归的终止条件为 target <= 0 或者
candidates
数组被全部用完。那么在当前的函数中,每次我们可以选择跳过不用第 idx
个数,即执行
dfs(target, combine, idx + 1)。也可以选择使用第 idx
个数,即执行
dfs(target - candidates[idx], combine, idx),注意到每个数字可以被无限制重复选取,因此搜索的下标仍为
idx。
更形象化地说,如果我们将整个搜索过程用一个树来表达,即如下图呈现,每次的搜索都会延伸出两个分叉,直到递归的终止条件,这样我们就能不重复且不遗漏地找到所有可行解:
代码
1 | class Solution { |
复杂度分析
时间复杂度:O(S),其中 S 为所有可行解的长度之和。从分析给出的搜索树我们可以看出时间复杂度取决于搜索树所有叶子节点的深度之和,即所有可行解的长度之和。在这题中,我们很难给出一个比较紧的上界,我们知道O(n×2^n) 是一个比较松的上界,即在这份代码中,n个位置每次考虑选或者不选,如果符合条件,就加入答案的时间代价。但是实际运行的时候,因为不可能所有的解都满足条件,递归的时候我们还会用
target - candidates[idx] >= 0进行剪枝,所以实际运行情况是远远小于这个上界的。空间复杂度:O(target)。除答案数组外,空间复杂度取决于递归的栈深度,在最差情况下需要递归 O(target) 层。
问题II
给定一个数组 candidates 和一个目标数 target
,找出 candidates 中所有可以使数字和为 target
的组合。
candidates 中的每个数字在每个组合中只能使用一次。
说明:
- 所有数字(包括目标数)都是正整数。
- 解集不能包含重复的组合。
示例 1:
1 | 输入: candidates = [10,1,2,7,6,1,5], target = 8, |
示例 2:
1 | 输入: candidates = [2,5,2,1,2], target = 5, |
思路与算法
由于我们需要求出所有和为 target 的组合,并且每个数只能使用一次,因此我们可以使用递归 + 回溯的方法来解决这个问题:
我们用
dfs(pos,rest)表示递归的函数,其中pos 表示我们当前递归到了数组 candidates 中的第pos个数,而rest表示我们还需要选择和为 rest 的数放入列表作为一个组合;对于当前的第pos个数,我们有两种方法:选或者不选。如果我们选了这个数,那么我们用
dfs(pos+1,rest−candidates[pos])进行递归,注意这里必须满足rest≥candidates[pos]。如果我们不选这个数,那么我们调用dfs(pos+1,rest)进行递归;在某次递归开始前,如果rest 的值为 0,说明我们找到了一个和为target 的组合,将其放入答案中。每次调用递归函数前,如果我们选了那个数,就需要将其放入列表的末尾,该列表中存储了我们选的所有数。在回溯时,如果我们选了那个数,就要将其从列表的末尾删除。
上述算法就是一个标准的递归 + 回溯算法,但是它并不适用于本题。这是因为题目描述中规定了解集不能包含重复的组合,而上述的算法中并没有去除重复的组合。
例如当candidates=[2,2],target=2 时,上述算法会将列表 [2] 放入答案两次。
因此,我们需要改进上述算法,在求出组合的过程中就进行去重的操作。我们可以考虑将相同的数放在一起进行处理,也就是说,如果数x 出现了y次,那么在递归时一次性地处理它们,即分别调用选择0,1,⋯,y 次 x 的递归函数。这样我们就不会得到重复的组合。具体地:
- 我们使用一个哈希映射(HashMap)统计数组candidates中每个数出现的次数。在统计完成之后,我们将结果放入一个列表freq中,方便后续的递归使用。
- 列表freq的长度即为数组candidates中不同数的个数。其中的每一项对应着哈希映射中的一个键值对,即某个数以及它出现的次数。
- 在递归时,对于当前的第pos个数,它的值为[0]freq[pos][0],出现的次数为freq[pos][1],那么我们可以调用
\[ \text{dfs}(\textit{pos}+1, \textit{rest} - i \times \textit{freq}[\textit{pos}][0]) \]
即我们选择了这个数 i 次。这里 i 不能大于这个数出现的次数,并且 i×freq[pos][0] 也不能大于rest。同时,我们需要将 i个freq[pos][0] 放入列表中。
这样一来,我们就可以不重复地枚举所有的组合了。
我们还可以进行什么优化(剪枝)呢?一种比较常用的优化方法是,我们将freq根据数从小到大排序,这样我们在递归时会先选择小的数,再选择大的数。这样做的好处是,当我们递归到dfs(pos,rest)
时,如果freq[pos][0]
已经大于rest,那么后面还没有递归到的数也都大于rest,这就说明不可能再选择若干个和为rest
的数放入列表了。此时,我们就可以直接回溯。
代码
1 | class Solution { |
复杂度分析
时间复杂度:
O(2^n×n),其中 n是数组 candidates 的长度。在大部分递归 + 回溯的题目中,我们无法给出一个严格的渐进紧界,故这里只分析一个较为宽松的渐进上界。在最坏的情况下,数组中的每个数都不相同,那么列表freq 的长度同样为n。在递归时,每个位置可以选或不选,如果数组中所有数的和不超target,那么 2^n 种组合都会被枚举到;在 target 小于数组中所有数的和时,我们并不能解析地算出满足题目要求的组合的数量,但我们知道每得到一个满足要求的组合,需要 O(n)的时间将其放入答案中,因此我们将 O(2^n)与 O(n)相乘,即可估算出一个宽松的时间复杂度上界。由于
O(2^n×n)在渐进意义下大于排序的时间复杂度O(nlogn),因此后者可以忽略不计。空间复杂度:O(n)。除了存储答案的数组外,我们需要 O(n)的空间存储列表 freq、递归中存储当前选择的数的列表、以及递归需要的栈。
问题III
找出所有相加之和为 n 的 k 个数的组合。组合中只允许含有 1 - 9 的正整数,并且每种组合中不存在重复的数字。
说明:
- 所有数字都是正整数。
- 解集不能包含重复的组合。
示例 1:
1 | 输入: k = 3, n = 7 |
示例 2:
1 | 输入: k = 3, n = 9 |
思路与算法
方法一:二进制(子集)枚举
「组合中只允许含有 1-91−9 的正整数,并且每种组合中不存在重复的数字」意味着这个组合中最多包含
9个数字。我们可以把原问题转化成集合 S = { 1,2,3,4,5,6,7,8,9
},我们要找出 S的当中满足如下条件的子集:
- 大小为 k
- 集合中元素的和为 n
因此我们可以用子集枚举的方法来做这道题。即原序列中有 9
个数,每个数都有两种状态,「被选择到子集中」和「不被选择到子集中」,所以状态的总数为
2^9 。我们用一个 9位二进制数 mask
来记录当前所有位置的状态,从第到高第 i位为 0 表示 i不被选择到子集中,为
1 表示 i 被选择到子集中。当我们按顺序枚举 [0, 2^9 - 1]
中的所有整数的时候,就可以不重不漏地把每个状态枚举到,对于一个状态
mask,我们可以用位运算的方法得到对应的子集序列,然后再判断是否满足上面的两个条件,如果满足,就记录答案。
如何通过位运算来得到mask 各个位置的信息?对于第 i 个位置我们可以判断
(1 << i) & mask 是否为 0,如果不为 0 则说明 i
在子集当中。当然,这里要注意的是,一个 9 位二进制数 i 的范围是 [0,
8],而可选择的数字是 [1,
9],所以我们需要做一个映射,最简单的办法就是当我们知道 i 位置不为 0
的时候将 i + 1加入子集。
代码
1 | class Solution { |
复杂度分析
- 时间复杂度:O(M×2^M),其中 M 为集合的大小,本题中 M 固定为 9。一共有 2^M个状态,每个状态需要 O(M + k) = O(M) 的判断 (k≤M)
- 空间复杂度:O(M)。即temp 的空间代价。
方法二:组合枚举
我们可以换一个思路:我们需要在 9 个数中选择 k 个数,让它们的和为 n。
这样问题就变成了一个组合枚举问题。组合枚举有两种处理方法——递归法和字典序法。
这里我们要做的是做一个「在 9 个数中选择 k 个数」的组合枚举,对于枚举到的所有组合,判断这个组合内元素之和是否为 n。
代码
1 | class Solution { |
复杂度分析
- 时间复杂度:
\[ O({M \choose k} \times k) \]
其中 M 为集合的大小,本题中 M 固定为 9。一共有 \[ M \choose k \] 个组合,每次判断需要的时间代价是 O(k)。
- 空间复杂度:O(M)。temp 数组的空间代价是 O(k),递归栈空间的代价是 O(M),故空间复杂度为 O(M + k) = O(M)
问题IV
给你一个由 不同 整数组成的数组 nums ,和一个目标整数
target 。请你从 nums 中找出并返回总和为
target 的元素组合的个数。
题目数据保证答案符合 32 位整数范围。
示例 1:
1 | 输入:nums = [1,2,3], target = 4 |
示例 2:
1 | 输入:nums = [9], target = 3 |
提示:
1 <= nums.length <= 2001 <= nums[i] <= 1000nums 中的所有元素互不相同1 <= target <= 1000
思路与算法
这道题中,给定数组nums 和目标值target,要求计算从 nums 中选取若干个元素,使得它们的和等于target 的方案数。其中,nums 的每个元素可以选取多次,且需要考虑选取元素的顺序。由于需要考虑选取元素的顺序,因此这道题需要计算的是选取元素的排列数。
可以通过动态规划的方法计算可能的方案数。用 dp[x] 表示选取的元素之和等于 x 的方案数,目标是求 dp[target]。
动态规划的边界是dp[0]=1。只有当不选取任何元素时,元素之和才为 0,因此只有 1 种方案。
当 1≤i≤target 时,如果存在一种排列,其中的元素之和等于 i,则该排列的最后一个元素一定是数组 nums 中的一个元素。假设该排列的最后一个元素是 num,则一定有 num≤i,对于元素之和等于i−num 的每一种排列,在最后添加 num 之后即可得到一个元素之和等于 i 的排列,因此在计算dp[i] 时,应该计算所有dp[i−num] 之和。
由此可以得到动态规划的做法:
初始化dp[0]=1;
遍历 i 从 1 到target,对于每个 i,进行如下操作:
遍历数组nums 中的每个元素 num,当num≤i 时,将dp[i−num] 的值加到 dp[i]。 最终得到dp[target] 的值即为答案。
上述做法是否考虑到选取元素的顺序?答案是肯定的。因为外层循环是遍历从 1 到 target 的值,内层循环是遍历数组 nums 的值,在计算dp[i] 的值时,nums 中的每个小于等于 i 的元素都可能作为元素之和等于 i 的排列的最后一个元素。例如,1 和 3 都在数组 nums 中,计算dp[4] 的时候,排列的最后一个元素可以是 1也可以是 3,因此 dp[1] 和 dp[3] 都会被考虑到,即不同的顺序都会被考虑到。
代码
1 | class Solution { |
复杂度分析
时间复杂度:O(target×n),其中 target 是目标值,n 是数组nums 的长度。需要计算长度为 target+1 的数组dp 的每个元素的值,对于每个元素,需要遍历数组nums 之后计算元素值。
空间复杂度:O(target)。需要创建长度为target+1 的数组dp。
来源:力扣(LeetCode)