本文提出了一种新颖的框架,用于通过一组一般功能来表示视频数据,这些功能是通过深度学习方法从较长的视频镜头中自动推断出来的。 具体而言,由卷积自动编码器堆栈组成的深度神经网络以无监督的方式处理视频帧,该视频帧捕获了数据中的空间结构,这些空间结构组合在一起构成了视频表示。 然后,该表示被馈送到卷积时间自动编码器的堆栈中,以学习规则的时间模式。
该方法的优点:
- 借助自动编码器,我们可以通过从数据中学习来找到代表性特征,而不是根据我们的知识来形成合适的特征。
- 用自动编码器代替了传统的稀疏编码方法。 与现有方法不同,在提取视频的特征表示与学习特征模型之间没有分离。 另外,通过在自动编码器中具有多层隐藏单元,可以实现分层特征学习。
过程:
相关工作:
与获取异常相比,由于在场景正常的情况下更容易获取视频数据,因此我们可以集中在训练数据仅包含正常视觉模式的设置上。 研究人员在该领域采用的一种流行方法是,首先从训练视频中学习正常模式,然后将异常检测为偏离正常模式的事件。 异常检测的大部分工作都依赖于从视频中提取局部特征,然后将其用于训练常态模型。
方法论:
此处描述的方法基于以下原理:当发生异常事件时,视频的最新帧将与旧帧明显不同。 该方法训练了一个端到端模型,该模型由空间特征提取器和时间编码器/解码器组成,它们一起学习输入帧的时间模式。 使用仅由正常场景组成的视频量训练模型,目的是最大程度地减少输入视频量与通过学习模型重建的输出视频量之间的重建误差。 正确训练模型后,正常视频量的重构误差较小,而包含异常场景的视频量的重构误差较高。 通过对每个测试输入量产生的错误进行阈值处理,我们的系统将能够检测到何时发生异常事件。
预处理:
这一阶段的任务是将原始数据转换为模型的对齐和可接受的输入。每一帧都从原始视频中提取,并调整为227×227的大小。为了确保输入的图像都在同一尺度上,像素值在0和1之间进行缩放,每一帧都要从其全局平均图像中减去,以实现标准化。平均图像是通过对训练数据集中每一帧的每个位置的像素值进行平均来计算的。之后,图像被转换为灰度以降低维度。然后,处理过的图像被归一化,使其具有零平均值和单位方差。
该模型的输入是视频的volumes,每个volume由10个连续的帧和不同的跳步组成。由于该模型的参数数量很大,因此需要大量的训练数据。我们在时间维度上进行数据扩充以增加训练数据集的大小。为了生成这些volume,我们将带有stide-1、stide-2和stide-3的帧连接起来。例如,第一个stride-1序列由帧{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}组成,而第一个stride-2序列包含帧号{1, 3, 5, 7, 9, 11, 13, 15, 17, 19},而stride-3序列将包含帧号{1, 4, 7, 10, 13, 16, 19, 22, 25, 28}。现在,输入已经准备好进行模型训练了。
特征学习:
我们提出了卷积时空自动编码器,以学习训练视频中的常规模式。 我们提出的体系结构由两部分组成:用于学习每个视频帧空间结构的空间自动编码器和用于学习已编码空间结构的时间模式的时间编码器-解码器。 如图1和2所示,空间编码器和解码器分别具有两个卷积和反卷积层,而时间编码器是三层卷积长期短期记忆(LSTM)模型。 卷积层以其在对象识别方面的卓越性能而闻名,而LSTM模型则广泛用于序列学习和时间序列建模,并已证明其在语音翻译和手写识别等应用中的性能。
自编码器
自动编码器,顾名思义,包括两个阶段:编码和解码。它最初是通过将编码器输出单元的数量设置为小于输入来降低维度。该模型通常采用无监督的反向传播方式进行训练,最大限度地减小原始输入解码结果的重构误差。当激活函数选择为非线性时,自编码器可以比常用的线性变换方法(如PCA)提取更多有用的特征。
空间卷积
对于卷积网络来说,卷积的主要目的是从输入图像中提取特征。卷积通过使用输入数据的小平方来学习图像特征来保持像素之间的空间关系。在数学上,卷积操作在滤波器和输入的局部区域之间进行点积。假设我们有一个n × n平方的输入层,后面是卷积层。如果使用m × m滤波器W,卷积层输出大小为(n−m+ 1)×(n−m+ 1)。
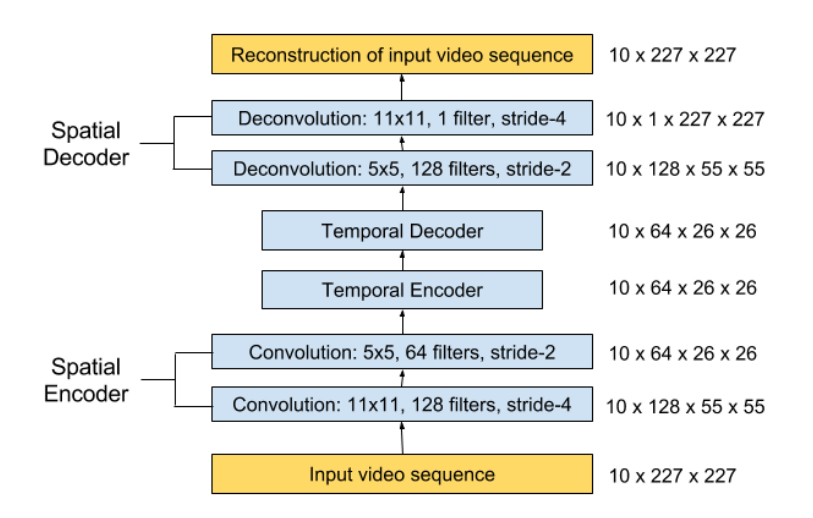
图1:我们提议的网络架构。它以一个长度为T的序列作为输入,输出输入序列的重构。最右边的数字表示每一层的输出大小。空间编码器每次以一帧为输入,处理T = 10帧后,将10帧的编码特征串接并送入时间编码器进行运动编码。解码器与编码器镜像以重建视频音量。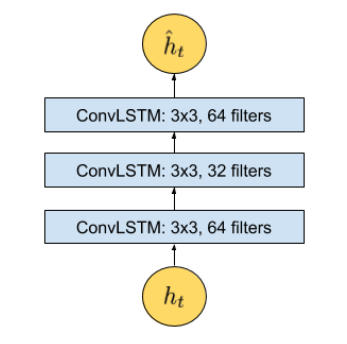
图2:时刻t的放大架构,其中t是这个时刻步骤的输入向量。时序编解码器模型有3个卷积LSTM (Conv LSTM)层。LSTM(Long Short Term Memory)长期短期记忆
在传统的前馈神经网络中,我们假设所有输入(和输出)彼此独立。 但是,学习输入之间的时间依赖性在涉及序列的任务中很重要,例如,单词预测器模型应该能够从过去的输入中获取信息。 RNN的工作原理与前馈网络相同,不同之处在于RNN的输出矢量的值不仅受输入矢量的影响,而且还受输入的整个历史的影响。 从理论上讲,RNN可以按任意长的顺序使用信息,但是在实践中,由于梯度逐渐消失,它们仅限于回顾一些步骤。(梯度消失和梯度爆炸)
为了克服这一问题,引入了RNN的一种变体:LSTM模型,该模型包含一个称为遗忘门的循环门。利用新的结构,lstm可以防止反向传播的错误消失或爆发,因此可以在长序列上工作,并可以将它们叠加在一起以捕获更高层次的信息。典型LSTM单元的计算公式如图3及式(1)至式(6)所示。
式(1)表示遗忘层,式(2)、式(3)为添加新信息的层,式(4)结合新旧信息,式(5)、式(6)则在下一个时间步向LSTM单元输出目前已经学习到的信息。变量xt为输入向量,ht为隐藏状态,Ct为t时刻的单元状态。W为可训练权矩阵,b为偏置向量,符号⊗为Hadamard积。 \[ f_t= σ(W_f⊗ [h_{t−1}, x_t] + b_f) \tag{1} \]
\[ i_t= σ(W_i⊗ [h_{t−1}, x_t] + b_i)\tag{2} \]
\[ \hat{C}_t= tanh(W_C⊗ [h_{t−1}, x_t] + b_C) \tag{3} \]
\[ C_t= f_t⊗ C_{t−1}+ i_t⊗\hat{C}_t\tag{4} \]
\[ o_t= σ(W_o⊗ [h_{t−1}, x_t] + b_o)\tag{5} \]
\[ h_t= o_t⊗ tanh(C_t)\tag{6} \]
LSTM有三个门:输入门,输出门,遗忘门。网络主要通过学习对这三者的控制来得到理想的结果。 有些实现细节,如果是多层结构的话,每个LSTM计算单元向上层传递的是h值。
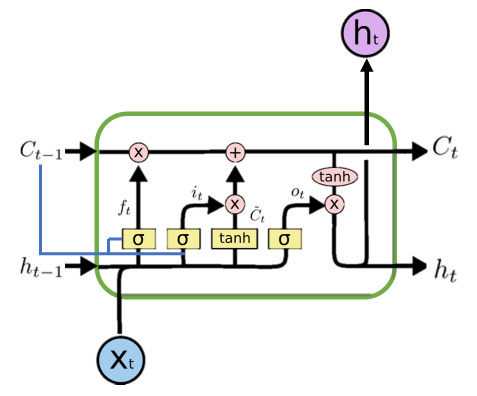
图3:一个典型的LSTM单元的结构。蓝线代表一个可选的窥视孔结构,它允许内部状态回看(窥视)之前的单元状态Ct-1以做出更好的决定。Hadamard 乘积
反向传播算法基于常规的线性代数运算 —— 诸如向量加法,向量矩阵乘法等。但是有一个运算不大常见: \[ \left[ \begin{matrix} 1\\2 \end{matrix} \right]⊙\left[ \begin{matrix} 3\\4 \end{matrix} \right]=\left[ \begin{matrix} 1*3\\2*4 \end{matrix} \right]=\left[ \begin{matrix} 3\\8 \end{matrix} \right]\tag{1} \] 这种类型的按元素乘法有时候被称为 Hadamard 乘积,或者 Schur 乘积。我们这里取前者。好的矩阵库通常会提供 Hadamard 乘积的快速实现,在实现反向传播的时候用起来很方便。
卷积LSTM
与通常的全连接LSTM (FC-LSTM)相比,ConvLSTM将其矩阵操作替换为卷积。通过对输入到隐藏和隐藏到隐藏连接使用卷积,ConvLSTM需要更少的权值,产生更好的空间特征映射。ConvLSTM单元的公式可归纳为(7)~(12)。 \[ f_t= σ(W_f∗ [h_{t−1}, x_t, C_{t−1}] + b_f)\tag{7} \]
\[ i_t= σ(W_i∗ [h_{t−1}, x_t, C_{t−1}] + b_i)\tag{8} \]
\[ \hat{C}_t= tanh(W_C∗ [h_{t−1}, x_t] + b_C)\tag{9} \]
\[ C_t= f_t⊗ C_{t−1}+ i_t⊗\hat{C}t\tag{10} \]
\[ o_t= σ(W_o∗ [h_{t−1}, x_t, C_{t−1}] + b_o)\tag{11} \]
\[ h_t= o_t⊗ tanh(C_t)\tag{12} \]
虽然方程在本质上与(1)到(6)相似,但输入以图像的形式输入,而每个连接的权值集被卷积滤波器代替(符号∗表示卷积操作)。这使得ConvLSTM能够比FC-LSTM更好地处理图像,因为它能够通过每个ConvLSTM状态在时间上传播空间特征。 ConvLSTM是LSTM的变体,改变主要是W的权值计算变成了卷积运算,这样可以提取出图像的特征。还有值得注意的是,LSTM计算单元内的权值是共享的,每层LSTM都共享一份权值。
请注意,这种卷积变体还添加了一个可选的“窥视孔
(peephole)”连接,使每个单元能够更好地获取过去的信息。
评估:
一旦模型经过训练,我们可以通过输入测试数据来评估模型的性能,并检查模型是否能够在保持低误报率的情况下检测到异常事件。将视频序列第t帧中所有像素值I的重构误差取为输入帧与重构帧之间的欧氏距离:
\[
e(t) = ||x(t) − f_W(x(t))||_2\tag{13}
\]
其中fw是通过时空模型学习到的权重。然后我们通过0到1之间的比例计算异常评分sa(t)。随后,规则性评分sr(t)由1简单减去异常评分得到:
\[
s_a(t) =\frac{e(t) − e(t){min}}
{e(t)_{max}}\tag{14}
\]
\[ s_r(t) = 1 − s_a(t)\tag{15} \]
LSTM详解:
Recurrent Neural Networks (RNN)
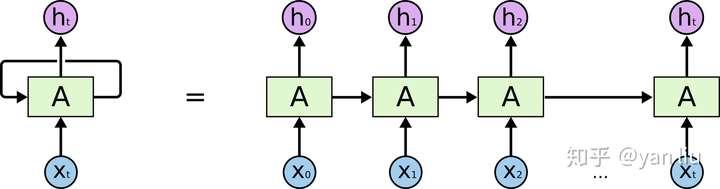
在使用深度学习处理时序问题时,RNN是最常使用的模型之一。RNN之所以在时序数据上有着优异的表现是因为RNN在\(t\)时间片时会将\(t-1\)时间片的隐节点作为当前时间片的输入,也就是RNN具有图1的结构。这样有效的原因是之前时间片的信息也用于计算当前时间片的内容,而传统模型的隐节点的输出只取决于当前时间片的输入特征。
RNN的数学表达式可以表示为
而传统的DNN的隐节点表示为
对比RNN和DNN的隐节点的计算方式,我们发现唯一不同之处在于RNN将上个时间片的隐节点状态\(h_{t-1}\)也作为了神经网络单元的输入,这也是RNN擅长处理时序数据最重要的原因。
所以,RNN的隐节点\(h_{t-1}\)有两个作用
- 计算在该时刻的预测值 \(\hat{y_t}=\sigma(h_t*w+b)\)
- 计算下个时间片的隐节点状态\(h_t\)
RNN的该特性也使RNN在很多学术和工业前景,例如OCR,语音识别,股票预测等领域上有了十足的进展。
长期依赖(Long Term Dependencies)
在深度学习领域中(尤其是RNN),“长期依赖“问题是普遍存在的。长期依赖产生的原因是当神经网络的节点经过许多阶段的计算后,之前比较长的时间片的特征已经被覆盖,例如下面例子
1 | eg1: The cat, which already ate a bunch of food, was full. |
我们想预测'full'之前系动词的单复数情况,显然full是取决于第二个单词’cat‘的单复数情况,而非其前面的单词food。根据图1展示的RNN的结构,随着数据时间片的增加,RNN丧失了学习连接如此远的信息的能力(图2)。
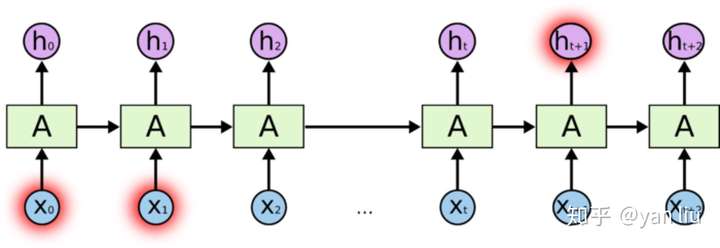
梯度消失/爆炸
梯度消失和梯度爆炸是困扰RNN模型训练的关键原因之一,产生梯度消失和梯度爆炸是由于RNN的权值矩阵循环相乘导致的,相同函数的多次组合会导致极端的非线性行为。梯度消失和梯度爆炸主要存在RNN中,因为RNN中每个时间片使用相同的权值矩阵。对于一个DNN,虽然也涉及多个矩阵的相乘,但是通过精心设计权值的比例可以避免梯度消失和梯度爆炸的问题 [2]。
处理梯度爆炸可以采用梯度截断的方法。所谓梯度截断是指将梯度值超过阈值\(\theta\)的梯度手动降到\(\theta\)。虽然梯度截断会一定程度上改变梯度的方向,但梯度截断的方向依旧是朝向损失函数减小的方向。
对比梯度爆炸,梯度消失不能简单的通过类似梯度截断的阈值式方法来解决,因为长期依赖的现象也会产生很小的梯度。在上面例子中,我们希望\(t_9\)时刻能够读到\(t_1\)时刻的特征,在这期间内我们自然不希望隐层节点状态发生很大的变化,所以\([t_2,t_8]\)时刻的梯度要尽可能的小才能保证梯度变化小。很明显,如果我们刻意提高小梯度的值将会使模型失去捕捉长期依赖的能力。
LSTM
LSTM的全称是Long Short Term Memory,顾名思义,它具有记忆长短期信息的能力的神经网络。LSTM首先在1997年由Hochreiter & Schmidhuber [1] 提出,由于深度学习在2012年的兴起,LSTM又经过了若干代大牛(Felix Gers, Fred Cummins, Santiago Fernandez, Justin Bayer, Daan Wierstra, Julian Togelius, Faustino Gomez, Matteo Gagliolo, and Alex Gloves)的发展,由此便形成了比较系统且完整的LSTM框架,并且在很多领域得到了广泛的应用。本文着重介绍深度学习时代的LSTM。
LSTM提出的动机是为了解决上面我们提到的长期依赖问题。传统的RNN节点输出仅由权值,偏置以及激活函数决定(图3)。RNN是一个链式结构,每个时间片使用的是相同的参数。
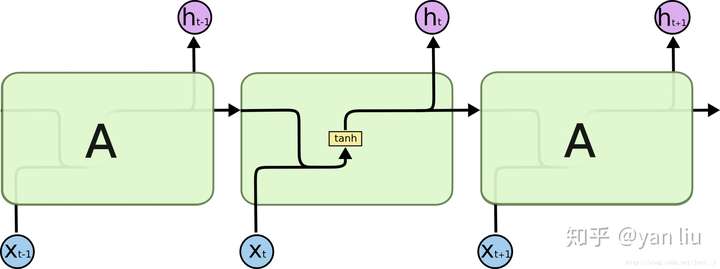
而LSTM之所以能够解决RNN的长期依赖问题,是因为LSTM引入了门(gate)机制用于控制特征的流通和损失。对于上面的例子,LSTM可以做到在t9时刻将t2时刻的特征传过来,这样就可以非常有效的判断\(t_9\)时刻使用单数还是复数了。LSTM是由一系列LSTM单元(LSTM Unit)组成,其链式结构如下图。
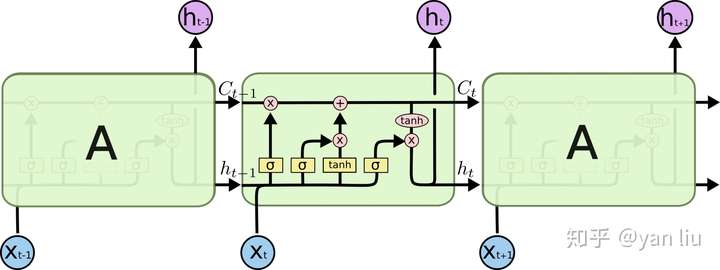
在后面的章节中我们再对LSTM的详细结构进行讲解,首先我们先弄明白LSTM单元中的每个符号的含义。每个黄色方框表示一个神经网络层,由权值,偏置以及激活函数组成;每个粉色圆圈表示元素级别操作;箭头表示向量流向;相交的箭头表示向量的拼接;分叉的箭头表示向量的复制。总结如图5.

LSTM的核心部分是在图4中最上边类似于传送带的部分(图6),这一部分一般叫做单元状态(cell state)它自始至终存在于LSTM的整个链式系统中。
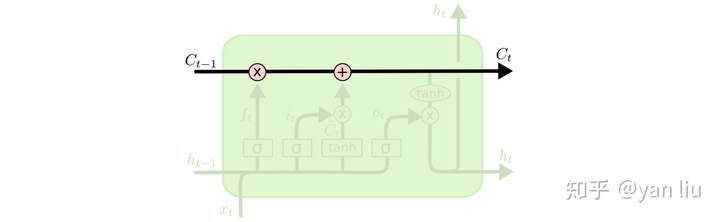
其中
其中\(f_t\)叫做遗忘门,表示\(C_{t-1}\)哪些特征被用于计算\(C_t\)。\(f_t\)是一个向量,向量的每个元素均位于\([0,1]\)范围内。通常我们使用\(sigmoid\)作为激活函数, \(sigmoid\) 的输出是一个介于 \([0,1]\) 区间内的值,但是当你观察一个训练好的LSTM时,你会发现门的值绝大多数都非常接近0或者1,其余的值少之又少。其中⊗是LSTM最重要的门机制,表示 \(f_t\)和\(C_{t-1}\)之间的单位乘的关系。
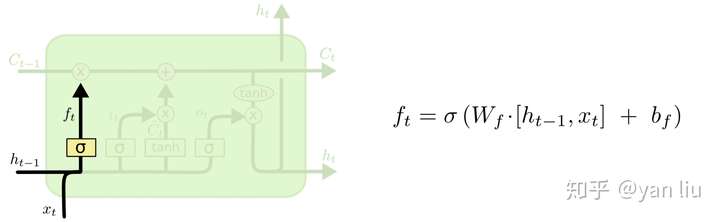
如图8所示,\(\hat{C_t}\)表示单元状态更新值,由输入数据\(x_t\)和隐节点\(h_{t-1}\)经由一个神经网络层得到,单元状态更新值的激活函数通常使用\(tanh\)。\(i_t\)叫做输入门,同\(f_t\) 一样也是一个元素介于\([0,1]\)区间内的向量,同样由\(x_t\)和 \(h_{t-1}\)经由\(sigmoid\)激活函数计算而成。
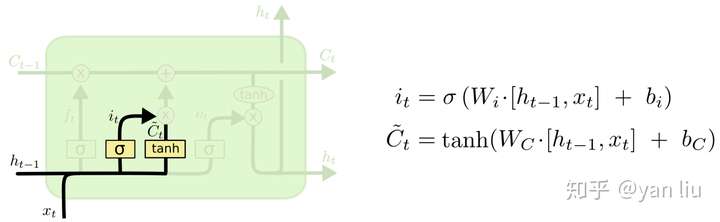
\(i_t\) 用于控制\(\hat{C_t}\)的哪些特征用于更新 \(C_t\),使用方式和\(f_t\)相同(图9)。
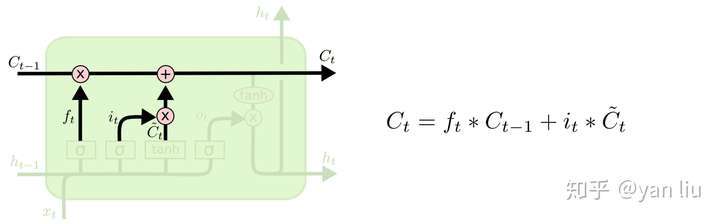
最后,为了计算预测值\(\hat{y_t}\)和生成下个时间片完整的输入,我们需要计算隐节点的输出 \(h_t\)(图10)。
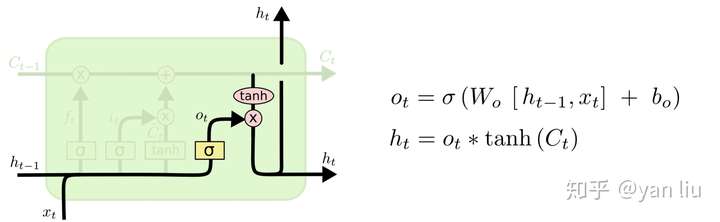
\(h_t\)由输出门\(o_t\)和单元状态\(C_t\)得到,其中\(o_t\)的计算方式和\(f_t\)以及\(i_t\)相同。在[3]的论文中指出,通过将\(b_o\)的均值初始化为1,可以使LSTM达到同GRU近似的效果。
其他LSTM
联想之前介绍的GRU [4],LSTM的隐层节点的门的数量和工作方式貌似是非常灵活的,那么是否存在一个最好的结构模型或者比LSTM和GRU性能更好的模型呢?Rafal[5] 等人采集了能采集到的100个最好模型,然后在这100个模型的基础上通过变异的形式产生了10000个新的模型。然后通过在字符串,结构化文档,语言模型,音频4个场景的实验比较了这10000多个模型,得出的重要结论总结如下:
- GRU,LSTM是表现最好的模型;
- GRU的在除了语言模型的场景中表现均超过LSTM;
- LSTM的输出门的偏置的均值初始化为1时,LSTM的性能接近GRU;
- 在LSTM中,门的重要性排序是遗忘门 > 输入门 > 输出门。
reference
[1] Hochreiter, S, and J. Schmidhuber. “Long short-term memory.” Neural Computation 9.8(1997):1735-1780.
[2] Sussillo, D. (2014). Random walks: Training very deep nonlinear feed-forward networks with smart initialization.CoRR,abs/1412.6558. 248, 259, 260, 344
[3] Gers F A, Schmidhuber J, Cummins F. Learning to forget: Continual prediction with LSTM[J]. 1999.
[4] Cho K, Van Merriënboer B, Gulcehre C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation[J]. arXiv preprint arXiv:1406.1078, 2014.
[5] Jozefowicz R, Zaremba W, Sutskever I. An empirical exploration of recurrent network architectures[C]//International Conference on Machine Learning. 2015: 2342-2350.
参考:详解LSTM