自编码器(Autoencoder,AE),是一种利用反向传播算法使得输出值等于输入值的神经网络,它先将输入压缩成潜在空间表征,然后通过这种表征来重构输出。
自编码器由两部分组成:
编码器:这部分能将输入压缩成潜在空间表征,可以用编码函数\(y=f(x)\)表示。
解码器:这部分能重构来自潜在空间表征的输入,可以用解码函数\(\hat{x}=g(y)\)表示。
因此,整个自编码器可以用函数\(g(f(x)) = \hat{x}\)来描述,其中输出r与原始输入x相近。
自编码简单模型介绍
暂且不谈神经网络、深度学习等,仅仅是自编码器的话,其原理其实很简单。自编码器可以理解为一个试图去还原其原始输入的系统。自编码器模型如下图所示。
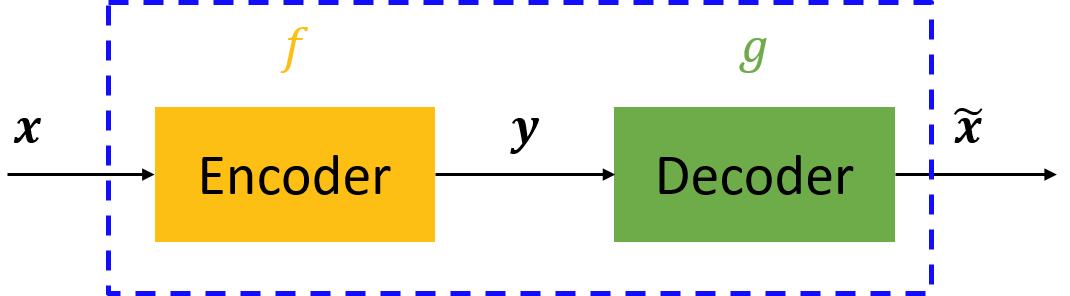
从上图可以看出,自编码器模型主要由编码器(Encoder)和解码器(Decoder)组成,其主要目的是将输入\(x\)转换成中间变量\(y\),然后再将\(y\)转换成\(\hat{x}\) ,然后对比输入\(x\)和输出 \(\hat{x}\) 使得他们两个无限接近。
为何要用输入来重构输出?
如果自编码器的唯一目的是让输出值等于输入值,那这个算法将毫无用处。事实上,我们希望通过训练输出值等于输入值的自编码器,让潜在表征y将具有价值属性。
这可通过在重构任务中构建约束来实现。
从自编码器获得有用特征的一种方法是,限制y的维度使其小于输入x,这种情况下称作有损自编码器。通过训练有损表征,使得自编码器能学习到数据中最重要的特征。
如果自编码器的容量过大,它无需提取关于数据分布的任何有用信息,即可较好地执行重构任务。
如果潜在表征的维度与输入相同,或是在过完备案例中潜在表征的维度大于输入,上述结果也会出现。
在这些情况下,即使只使用线性编码器和线性解码器,也能很好地利用输入重构输出,且无需了解有关数据分布的任何有用信息。
在理想情况下,根据要分配的数据复杂度,来准确选择编码器和解码器的编码维数和容量,就可以成功地训练出任何所需的自编码器结构。
自编码器用来干什么?
目前,自编码器的应用主要有两个方面,第一是数据去噪,第二是为进行可视化而降维。设置合适的维度和稀疏约束,自编码器可以学习到比PCA等技术更有意思的数据投影。
自编码器能从数据样本中进行无监督学习,这意味着可将这个算法应用到某个数据集中,来取得良好的性能,且不需要任何新的特征工程,只需要适当地训练数据。
但是,自编码器在图像压缩方面表现得不好。由于在某个给定数据集上训练自编码器,因此它在处理与训练集相类似的数据时可达到合理的压缩结果,但是在压缩差异较大的其他图像时效果不佳。这里,像JPEG这样的压缩技术在通用图像压缩方面会表现得更好。
训练自编码器,可以使输入通过编码器和解码器后,保留尽可能多的信息,但也可以训练自编码器来使新表征具有多种不同的属性。不同类型的自编码器旨在实现不同类型的属性。下面将重点介绍四种不同的自编码器。
自编码器与神经网络
简单来讲,神经网络就是在对原始信号逐层地做非线性变换,如下图所示。
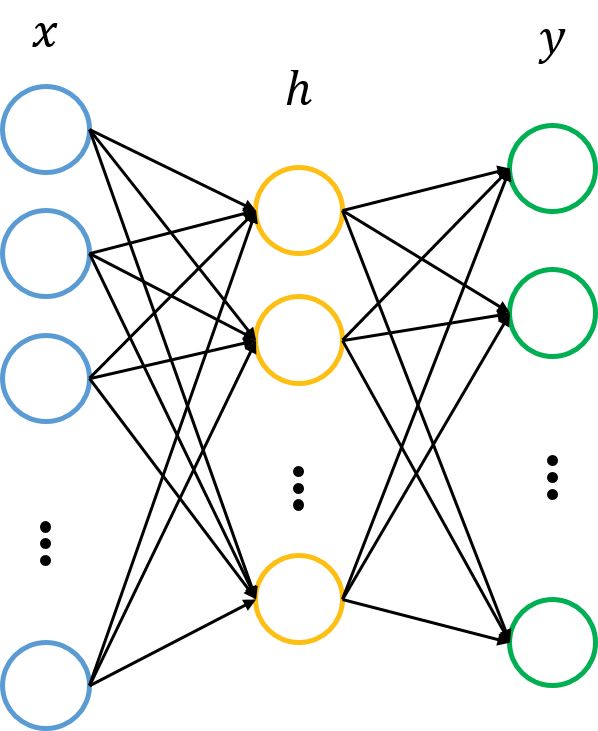
该网络把输入层数据\(x∈R_n\)转换到中间层(隐层)\(h∈R_p\),再转换到输出层\(y∈R_m\)。图中的每个节点代表数据的一个维度(偏置项图中未标出)。每两层之间的变换都是“线性变化”+“非线性激活”,用公式表示即为 \[ h=f(W(1)x+b(1)) y=f(W(2)h+b(2)) \] 神经网络往往用于分类,其目的是去逼近从输入层到输出层的变换函数。因此,我们会定义一个目标函数来衡量当前的输出和真实结果的差异,利用该函数去逐步调整(如梯度下降)系统的参数\((W(1),b(1),W(2),b(2))\),以使得整个网络尽可能去拟合训练数据。如果有正则约束的话,还同时要求模型尽量简单(防止过拟合)。
那么,自编码器怎么表示呢?前面已说过,自编码器试图复现其原始输入,因此,在训练中,网络中的输出应与输入相同,即\(y=x\),因此,一个自编码器的输入、输出应有相同的结构,即
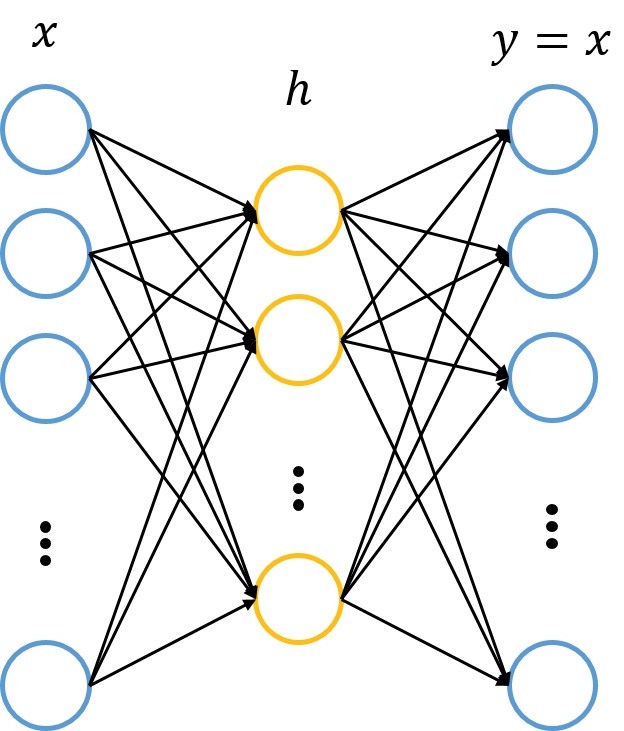
我们利用训练数据训练这个网络,等训练结束后,这个网络即学习出了x-→h- >x的能力。对我们来说,此时的h是至关重要的,因为它是在尽量不损失信息量的情况下,对原始数据的另-种表达。结合神经网络的惯例,我们再将自编码器的公式表示如下: (假设激活函数是\(sigmoid\), 用\(s\)表示) \[ y=f_\theta(x)=s(Wx+b)\\ \hat{x}=g_\theta^{'}(y)=s(W'y+b')\\ L(x,\hat{x}) =L(x,g(f(x)) \] 其中,L表示损失函数,结合数据的不同形式,可以是二次误差(squared error loss)或交叉熵误差(cross entropy loss)。如果\(w' = w^T\),一般称为tied weights。
为了尽学到有意义的表达,我们会给隐层加入一定的约束。从数据维度来看,常见以下两种情况:
- n>p,即隐层维度小于输入数据维度。也就是说从\(x→h\)的变换是一种降维的操作,网络试图以更小的维度去描述原始数据而尽量不损失数据信息。实际上,当每两层之间的变换均为线性,且监督训练的误差是二次型误差时, 该网络等价于PCA。
- n<p,即隐层维度大于输入数据维度。这又有什么用呢?其实不好说,但比如我们同时约束\(h\)的表达尽量稀疏(有大量维度为0,未被激活),此时的编码器便是大名鼎鼎的“稀疏自编码器”。可为什么稀疏的表达就是好的?这就说来话长了,有人试图从人脑机理对比,即人类神经系统在某刺激下,大部分神经元是被抑制的。个人觉得,从特征的角度来看更直观些,稀疏的表达意味着系统在尝试去特征选择,找出大量维度中真正重要的若干维。
神经网络自编码器三大特点
- 自动编码器是数据相关的(data-specific 或 data-dependent),这意味着自动编码器只能压缩那些与训练数据类似的数据。比如,使用人脸训练出来的自动编码器在压缩别的图片,比如树木时性能很差,因为它学习到的特征是与人脸相关的。
- 自动编码器是有损的,意思是解压缩的输出与原来的输入相比是退化的,MP3,JPEG等压缩算法也是如此。这与无损压缩算法不同。
- 自动编码器是从数据样本中自动学习的,这意味着很容易对指定类的输入训练出一种特定的编码器,而不需要完成任何新工作。
自编码器(Autoencoder)搭建
搭建一个自动编码器需要完成下面三样工作:搭建编码器,搭建解码器,设定一个损失函数,用以衡量由于压缩而损失掉的信息。编码器和解码器一般都是参数化的方程,并关于损失函数可导,典型情况是使用神经网络。编码器和解码器的参数可以通过最小化损失函数而优化,例如SGD。举个例子:根据上面介绍,自动编码器看作由两个级联网络组成。
第一个网络是一个编码器,负责接收输入 \(x\),并将输入通过函数 \(h\) 变换为信号 \(y\): \[ y=h(x) \] 第二个网络将编码的信号 \(y\) 作为其输入,通过函数\(f\)得到重构的信号 \(r\): \[ r=f(y)=f(h(x)) \] 定义误差 \(e\) 为原始输入 \(x\) 与重构信号 \(r\) 之差,\(e=x–r\),网络训练的目标是减少均方误差(MSE),同 MLP 一样,误差被反向传播回隐藏层。
四种不同的自编码器
本文将介绍以下四种不同的自编码器:
- 香草自编码器(基础自编码器)
- 多层自编码器
- 卷积自编码器
- 正则自编码器
为了说明不同类型的自编码器,推荐一个使用了Keras框架和MNIST数据集对每个类型分别创建了示例的代码:Yaka12/Autoencoders
香草自编码器
在这种自编码器的最简单结构中,只有三个网络层,即只有一个隐藏层的神经网络。它的输入和输出是相同的,可通过使用Adam优化器和均方误差损失函数,来学习如何重构输入。
在这里,如果隐含层维数(64)小于输入维数(784),则称这个编码器是有损的。通过这个约束,来迫使神经网络来学习数据的压缩表征。
1 | input_size = 784 |
多层自编码器
如果一个隐含层还不够,显然可以将自动编码器的隐含层数目进一步提高。
在这里,实现中使用了3个隐含层,而不是只有一个。任意一个隐含层都可以作为特征表征,但是为了使网络对称,我们使用了最中间的网络层。
1 | input_size = 784 |
卷积自编码器
你可能有个疑问,除了全连接层,自编码器应用到卷积层吗?
答案是肯定的,原理是一样的,但是要使用3D矢量(如图像)而不是展平后的一维矢量。对输入图像进行下采样,以提供较小维度的潜在表征,来迫使自编码器从压缩后的数据进行学习。
1 | x = Input(shape=(28, 28,1)) |
正则自编码器
除了施加一个比输入维度小的隐含层,一些其他方法也可用来约束自编码器重构,如正则自编码器。
正则自编码器不需要使用浅层的编码器和解码器以及小的编码维数来限制模型容量,而是使用损失函数来鼓励模型学习其他特性(除了将输入复制到输出)。这些特性包括稀疏表征、小导数表征、以及对噪声或输入缺失的鲁棒性。
即使模型容量大到足以学习一个无意义的恒等函数,非线性且过完备的正则自编码器仍然能够从数据中学到一些关于数据分布的有用信息。
在实际应用中,常用到两种正则自编码器,分别是稀疏自编码器和降噪自编码器。
稀疏自编码器:
一般用来学习特征,以便用于像分类这样的任务。稀疏正则化的自编码器必须反映训练数据集的独特统计特征,而不是简单地充当恒等函数。以这种方式训练,执行附带稀疏惩罚的复现任务可以得到能学习有用特征的模型。
还有一种用来约束自动编码器重构的方法,是对其损失函数施加约束。比如,可对损失函数添加一个正则化约束,这样能使自编码器学习到数据的稀疏表征。
要注意,在隐含层中,我们还加入了L1正则化,作为优化阶段中损失函数的惩罚项。与香草自编码器相比,这样操作后的数据表征更为稀疏。
1 | input_size = 784 |
降噪自编码器:
这里不是通过对损失函数施加惩罚项,而是通过改变损失函数的重构误差项来学习一些有用信息。
向训练数据加入噪声,并使自编码器学会去除这种噪声来获得没有被噪声污染过的真实输入。因此,这就迫使编码器学习提取最重要的特征并学习输入数据中更加鲁棒的表征,这也是它的泛化能力比一般编码器强的原因。
这种结构可以通过梯度下降算法来训练。
1 | x = Input(shape=(28, 28, 1)) |